Changes in 5.2 are mainly related to user interface and experience. The most visible change is the introduction of the ribbon menu system for providing easy access to most software features.
![1.png]()
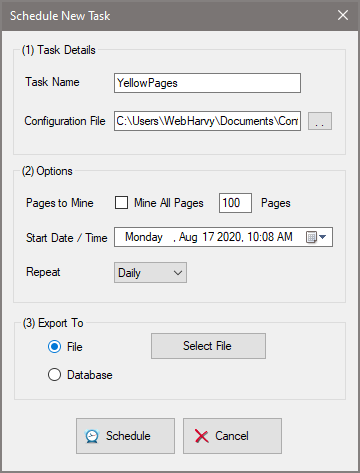
In addition to the main interface, other windows like Scheduler / Export etc. have also been updated. The export functionality (to file or database) has now been made cancel-able. User can now cancel an ongoing export to file or database.
As with every release, the Chrome browser has been updated as well. Issues related to URL update (in address bar) while navigating links in some websites has been fixed with this update.
An important non-UI feature addition in this release is the support added for exporting data to Oracle database. The default file export option is changed from CSV to Excel format.
All main settings are now displayed in snippet format in browser view’s status bar.
![smarthelp]()
Help (videos, articles) related to the website loaded in the configuration browser is automatically loaded and displayed as a smart tip.
Miner Settings can now be opened and changed directly from the Miner window.
![minersettings.png]()
JavaScript can now be typed in multi-line code format.
![js]()
Browser settings now include a new option to share user location to the loaded page.
![browsersetting.png]()
In addition to the above this release also contains minor bug fixes and improvements as always. You may download and try the latest version from https://www.webharvy.com/download.html